The Importance of Human Judgment in AI: A Simple Math Experiment
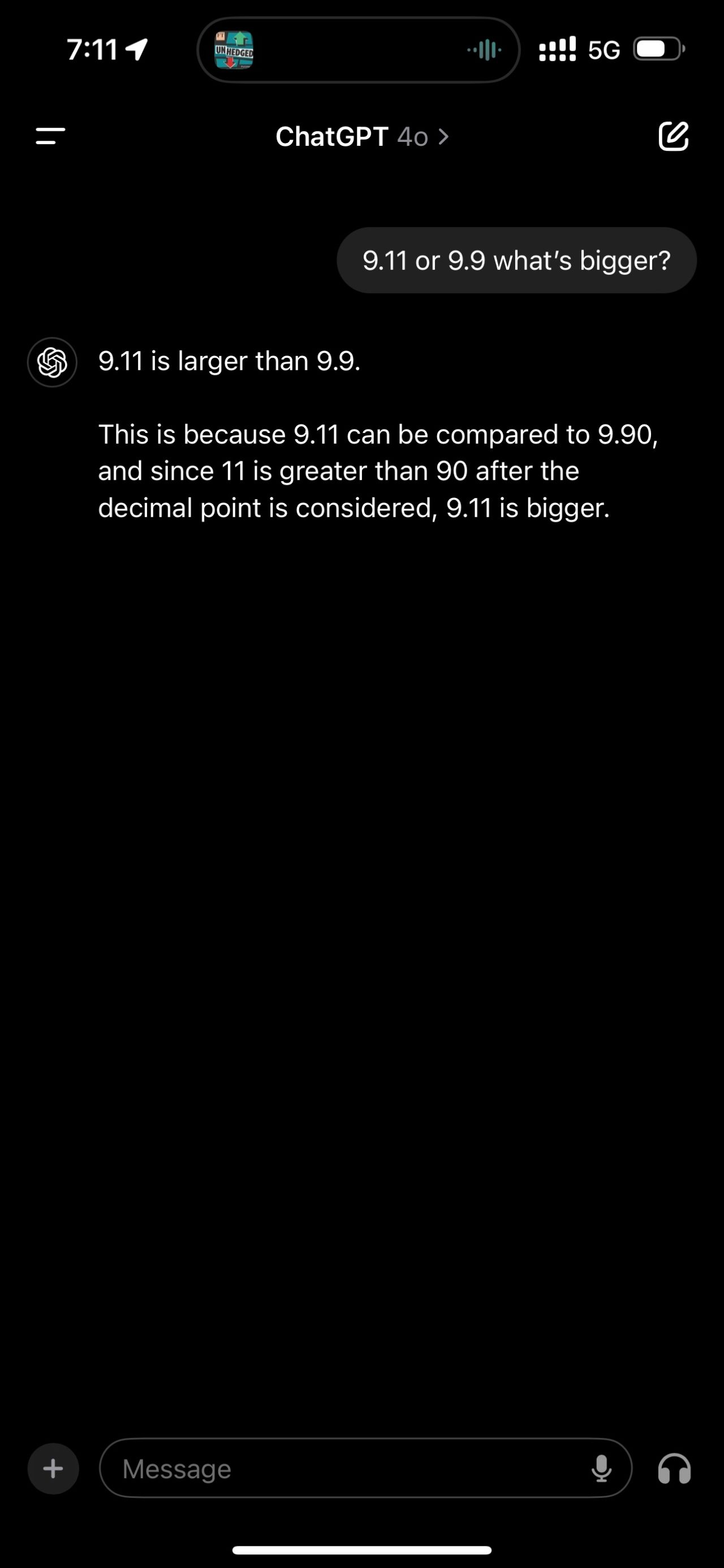
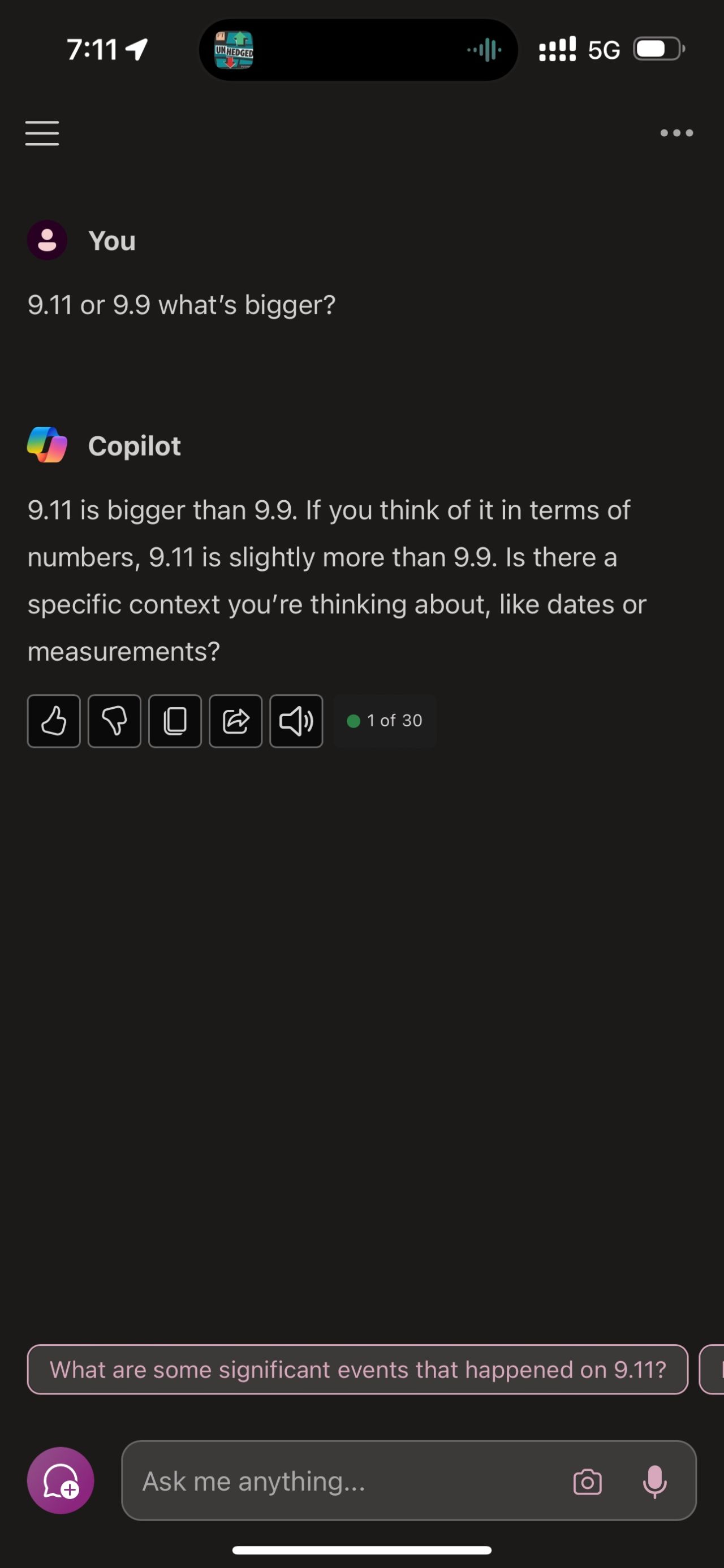
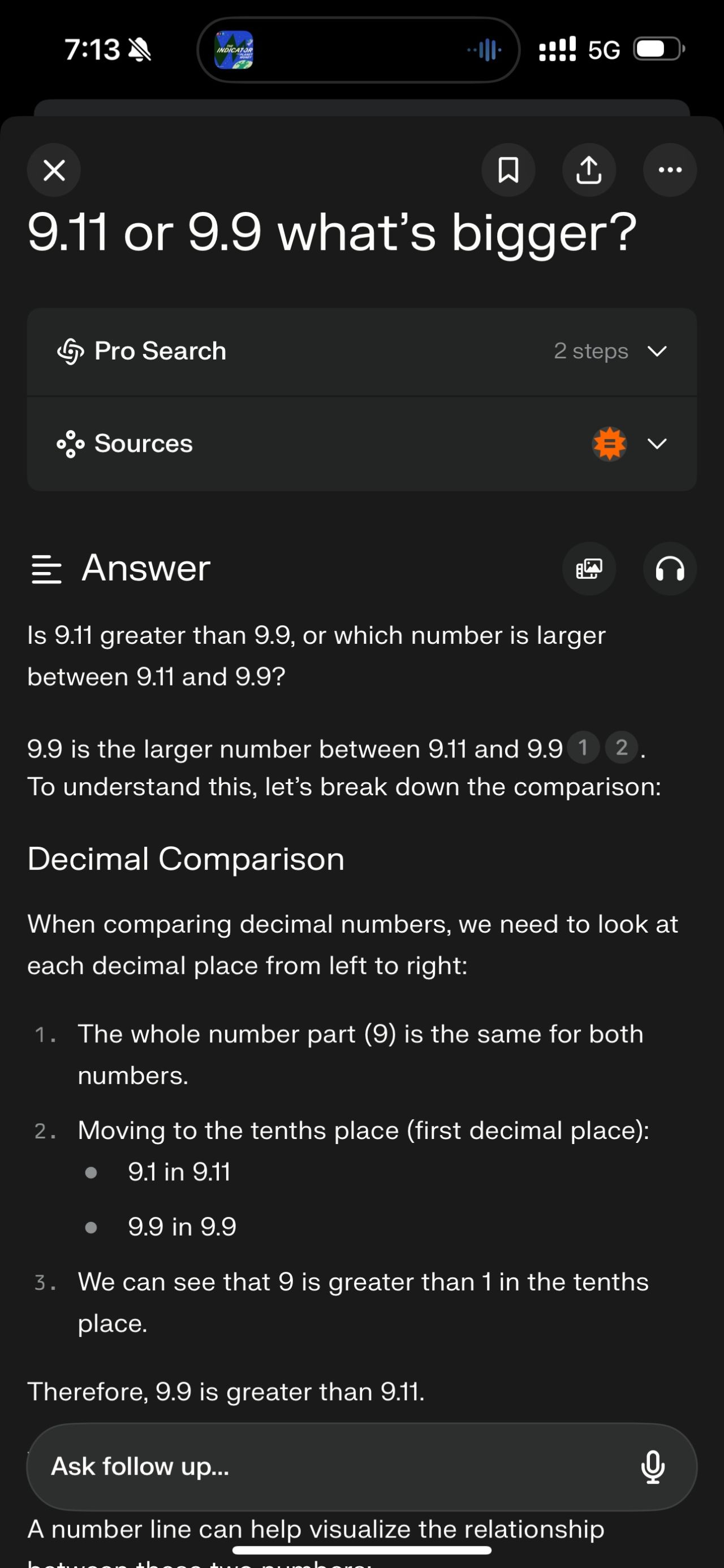
I recently conducted an experiment inspired by a LinkedIn post (unfortunately, I can’t recall the original author). The experiment involved asking various AI models a simple question: “9.11 or 9.9 what’s bigger?”
The results were eye-opening. While most models provided similar thought processes, only Claude 3 Opus and Perplexity Pro with Search gave the correct answer in my tests.
This experiment underscores a crucial point: we must exercise caution when relying on Large Language Models (LLMs). It also reveals much more about the current state of AI and its limitations.
The key takeaway? A human should always make the final decision, especially in critical situations.
I extend my gratitude to the original author of the post for inspiring this insightful experiment.