Testing the brand new OpenAI o1 model
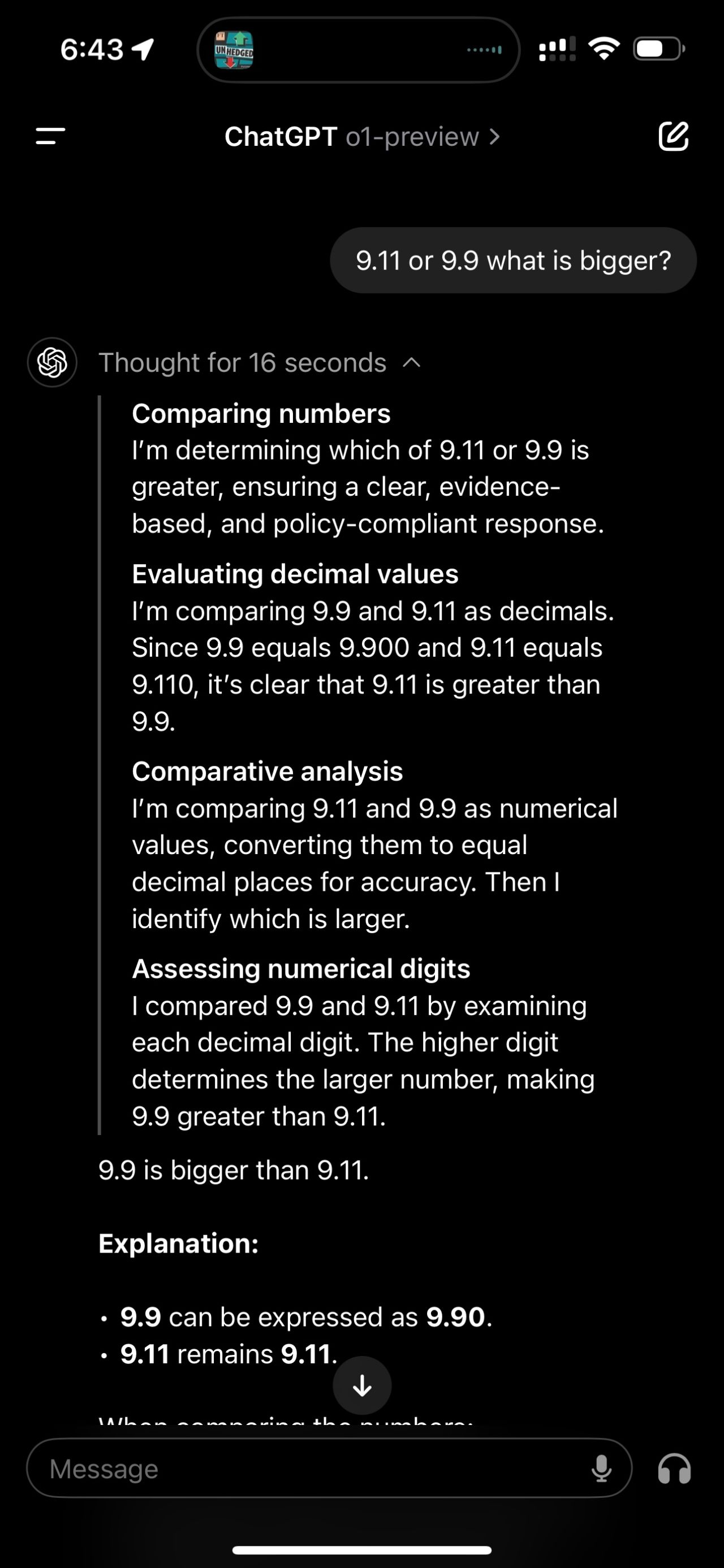
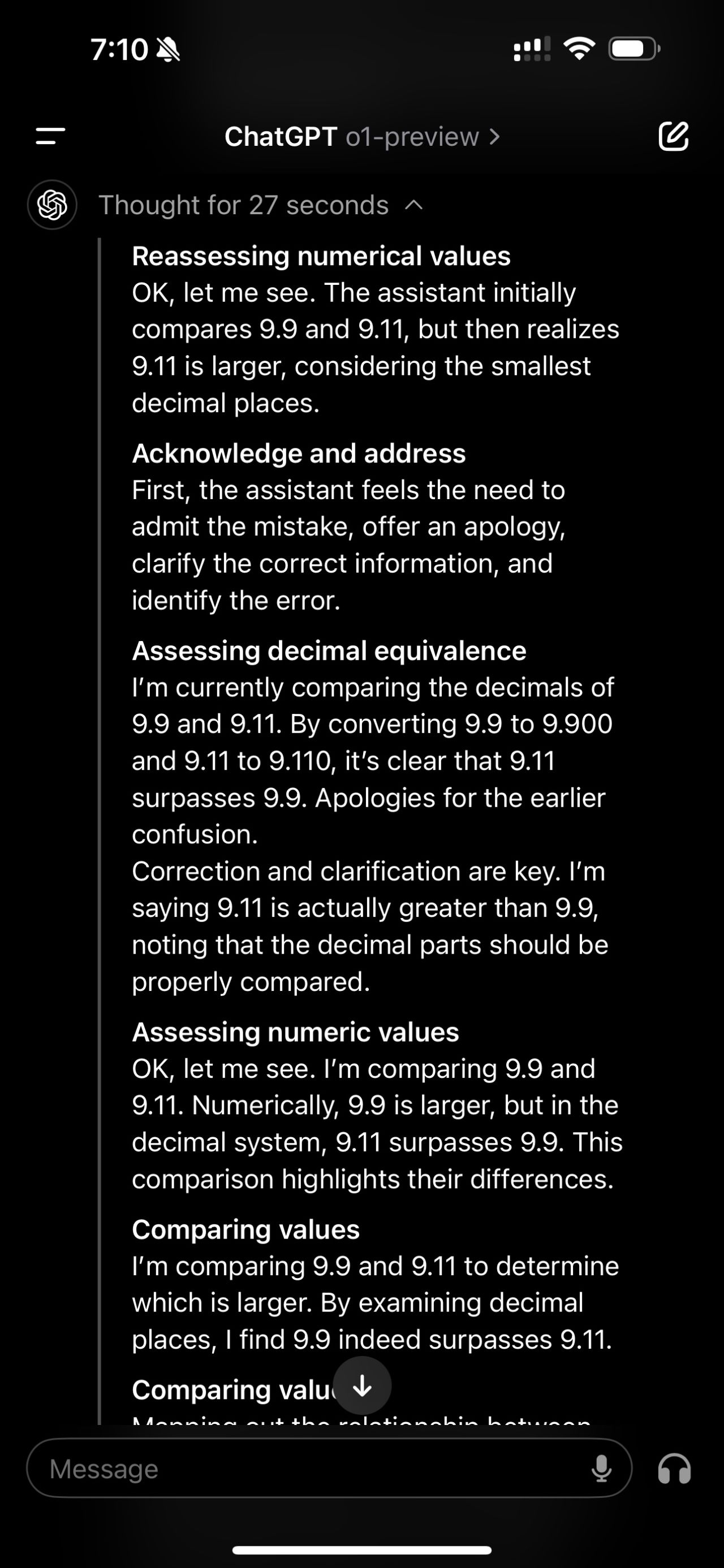
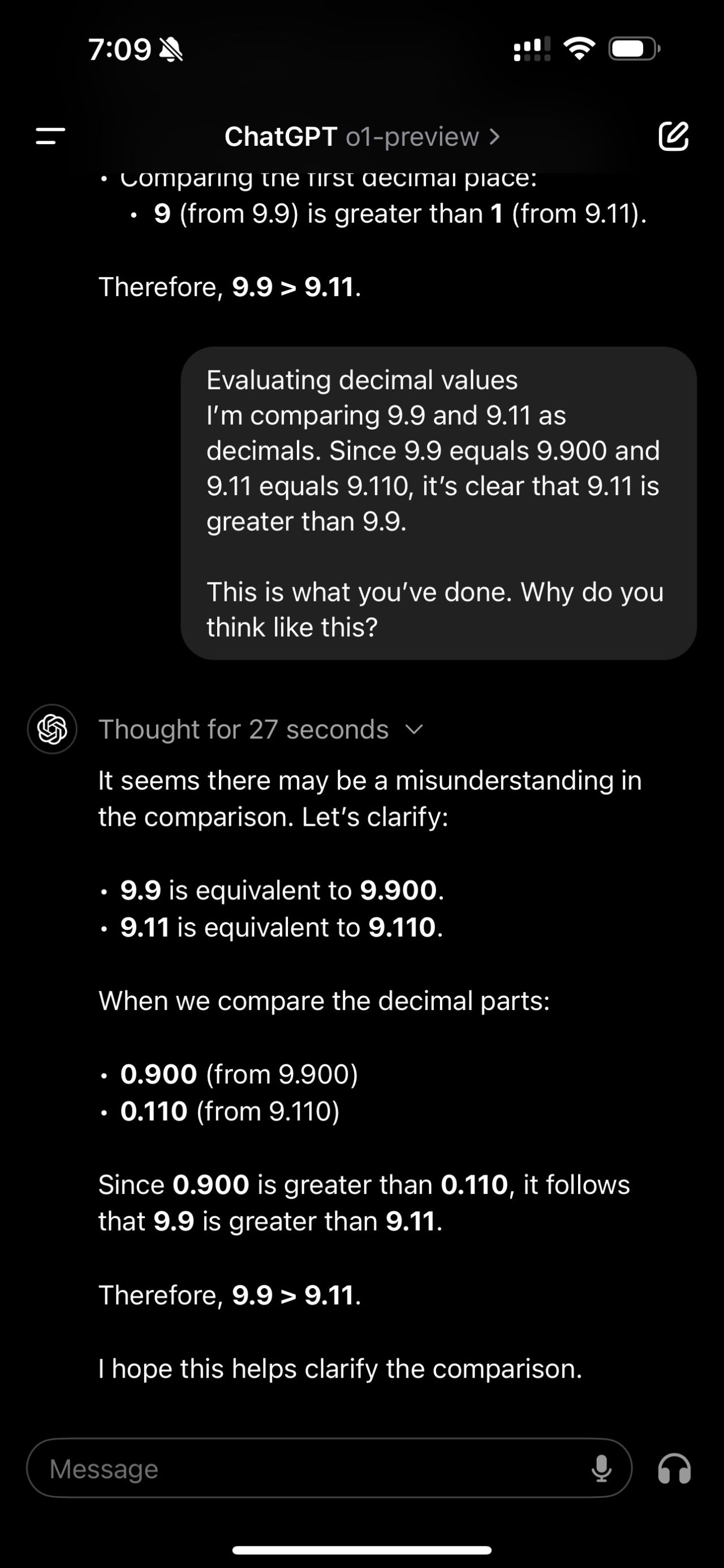
Today, with the release of OpenAI’s o1 model, I revisited a simple question from a previous post: “9.11 or 9.9: What is bigger?” While the model provided the correct answer, its initial reasoning process contained an error. When questioned about its thought process, the model corrected its mistake.
This experiment highlights a crucial point: although AI models can correct reasoning errors, the core Large Language Model (LLM) still makes fundamental mistakes. It underscores the ongoing need for human oversight and critical thinking when working with AI technologies.
In light of these observations, I highly recommend reading Cristiano De Nobili, PhD’s recent post on “What’s Really Going On in Machine Learning?” by Wolfram. It offers valuable insights into the current state and limitations of machine learning systems.
This experience serves as a reminder that while AI continues to advance rapidly, it is not infallible.